RadixArk and SGLang: Revolutionizing AI Inference Efficiency
The rapid proliferation of Large Language Models (LLMs) has ushered in a new era of artificial intelligence, but it has also brought to light significant computational challenges, particularly in the realm of AI inference. As LLMs grow in size and complexity, the resources required to run them efficiently—especially for real-time applications—become astronomical. This "inference bottleneck" has been a major hurdle for deploying advanced AI at scale. Enter RadixArk, a groundbreaking startup that has spun off from UC Berkeley, armed with its innovative SGLang engine, poised to dramatically enhance the efficiency of AI inference.
From Academia to Industry: The Birth of RadixArk
RadixArk emerged from the highly acclaimed SGLang open-source research project at UC Berkeley, a testament to the power of academic innovation transitioning into commercial application. The company has made a significant splash, securing a $100 million seed funding round at an impressive $400 million valuation [1]. This substantial investment underscores the market's recognition of SGLang's potential to solve one of the most pressing problems in AI today.
The leadership behind RadixArk is equally formidable. The company is spearheaded by Ying Sheng, a former employee of xAI, Elon Musk's AI venture, bringing invaluable industry experience and a deep understanding of frontier AI challenges. Guiding the project from its academic roots is Ion Stoica, a luminary in distributed systems and co-founder of Databricks and Anyscale. This combination of academic rigor, entrepreneurial drive, and industry expertise positions RadixArk to be a major player in the AI infrastructure landscape.
The Inference Bottleneck: A Growing Challenge
AI inference, the process of using a trained AI model to make predictions or decisions, is often more computationally intensive and costly than training, especially for large models. Traditional inference serving systems struggle with:
- Memory Bandwidth: LLMs require vast amounts of memory to store their parameters, and moving this data to and from the processing units (GPUs) is a major bottleneck.
- Latency: For real-time applications, responses must be generated almost instantaneously, which is difficult with large models.
- Throughput: Serving multiple requests concurrently while maintaining low latency is a complex optimization problem.
- Cost: The operational expenses associated with running large-scale LLM inference can be prohibitive for many organizations.
These challenges are particularly acute in agentic workflows, where LLMs interact with external tools and systems, requiring multiple, rapid inference calls. Existing solutions often lead to suboptimal performance and inflated costs.
SGLang and RadixAttention: The Core Innovation
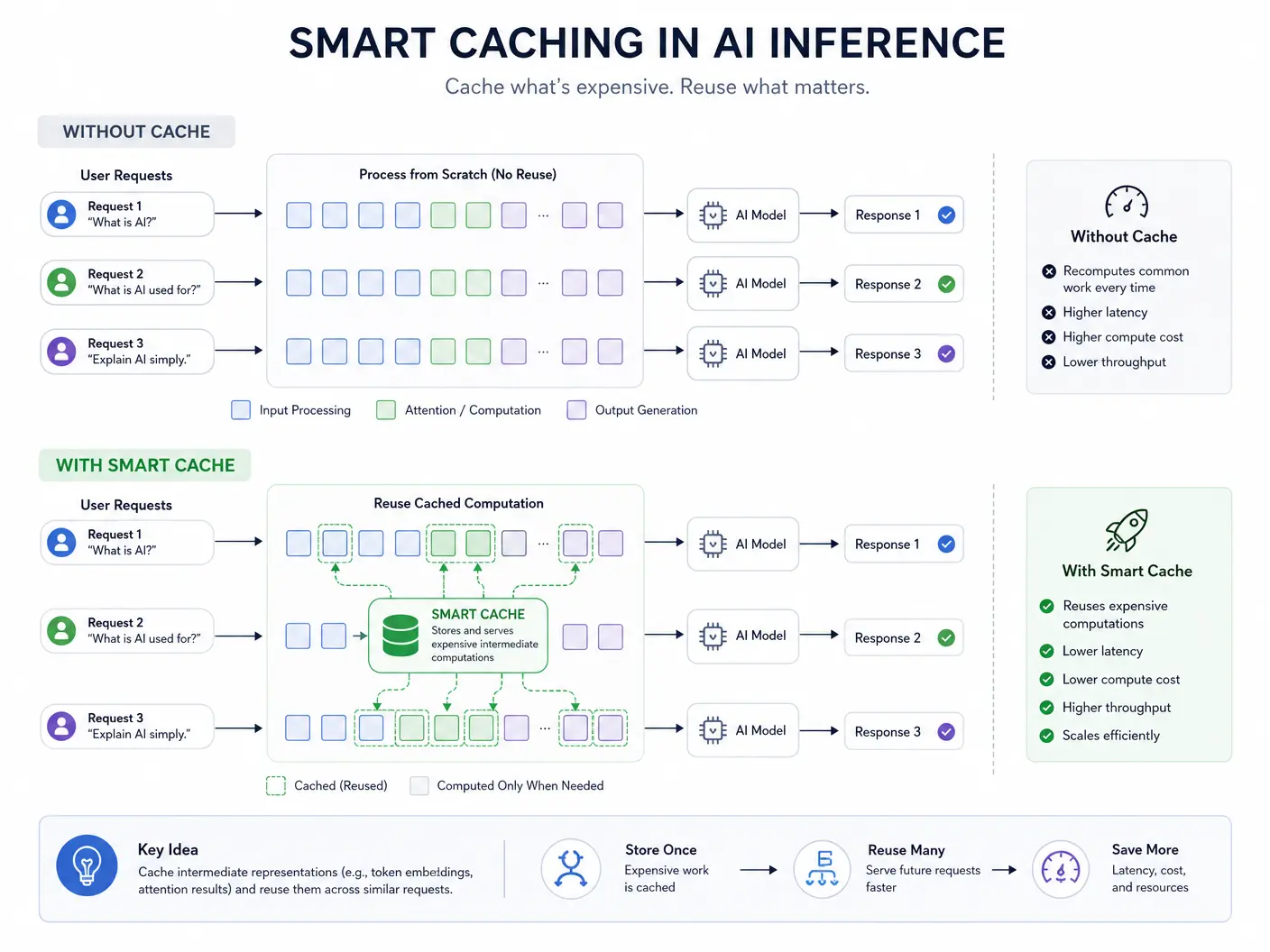
At the heart of RadixArk's solution is the SGLang engine, which leverages a novel technique called "RadixAttention". This approach introduces a sophisticated form of smart caching that fundamentally rethinks how attention mechanisms—a core component of transformer models—are handled during inference. Unlike conventional methods that recompute attention for every token, RadixAttention intelligently reuses previously computed attention states, drastically reducing redundant computations.
How RadixAttention Works:
- Smart Caching: RadixAttention maintains a dynamic cache of key-value pairs from previous tokens in a sequence. When new tokens are processed, the engine first checks the cache for relevant information.
- Efficient Reuse: Instead of re-calculating attention from scratch, it efficiently reuses cached states, significantly cutting down on memory access and computational load.
- Optimized for Agentic Workflows: This smart caching is particularly effective in agentic applications, where models often process similar prompts or engage in iterative reasoning, allowing for substantial performance gains.
The impact of SGLang with RadixAttention is profound. In complex agentic workflows, RadixArk has demonstrated performance improvements of up to 5 times faster than vLLM, a widely used high-performance inference engine [1]. This level of efficiency is a game-changer for organizations looking to deploy LLMs at scale without incurring exorbitant operational costs.
Broad Market Impact and Versatility
RadixArk's SGLang engine is not limited to a specific model or architecture. Its design allows it to support over 500 different model architectures, making it a versatile solution for a wide range of AI applications [1]. This broad compatibility means that hyperscalers, frontier labs, and enterprises can integrate SGLang into their existing infrastructure, optimizing their LLM deployments regardless of the specific models they are using.
The company's focus on solving the inference bottleneck addresses a critical need in the AI ecosystem. By making inference more efficient, RadixArk is contributing to:
- Democratization of Advanced AI: Lowering the cost and computational requirements of running LLMs makes advanced AI more accessible to a broader range of developers and businesses.
- Acceleration of AI Innovation: More efficient inference enables faster experimentation and deployment of new AI models and applications.
- Sustainable AI Deployment: Reducing the energy consumption associated with LLM inference contributes to more environmentally friendly AI operations.
The Future of AI Inference: A Competitive Edge
RadixArk's emergence signifies a crucial evolutionary step in the AI landscape. As LLMs continue to grow in size and capability, the ability to run them efficiently will become a key differentiator for companies. Organizations that can leverage solutions like SGLang will gain a significant competitive edge, enabling them to deliver faster, more cost-effective, and more scalable AI-powered products and services.
The venture capital community's enthusiastic response to RadixArk highlights the strategic importance of inference optimization. Investors are recognizing that while model development captures headlines, the practical deployment and operational efficiency of these models are where significant economic value will be created. With its strong technical foundation, experienced leadership, and proven performance gains, RadixArk is well-positioned to become a cornerstone of the next generation of AI infrastructure.
Conclusion:
RadixArk, with its innovative SGLang engine and RadixAttention technology, is set to redefine the landscape of AI inference. By tackling the critical challenges of memory bandwidth, latency, and throughput, the company is enabling significantly more efficient and scalable deployment of large language models. The substantial seed funding and the expertise of its leadership team underscore the profound impact RadixArk is expected to have on the AI industry. As AI continues its rapid expansion, solutions that optimize inference efficiency will be paramount, and RadixArk is at the forefront of this crucial technological advancement.
Author: Malik AI Team
Date: 2026-05-05