Multimodal Model Mastery
In the ever-evolving landscape of Artificial Intelligence, a new frontier is being conquered: the seamless integration of multiple data modalities. As of April 2026, the era of unimodal AI, where models specialized in processing only text, images, or audio, is rapidly giving way to multimodal models. These advanced systems are capable of understanding and generating content across various data types—text, vision, audio, and even action—creating a more holistic and human-like comprehension of the world. This represents a significant leap towards truly intelligent and versatile AI.
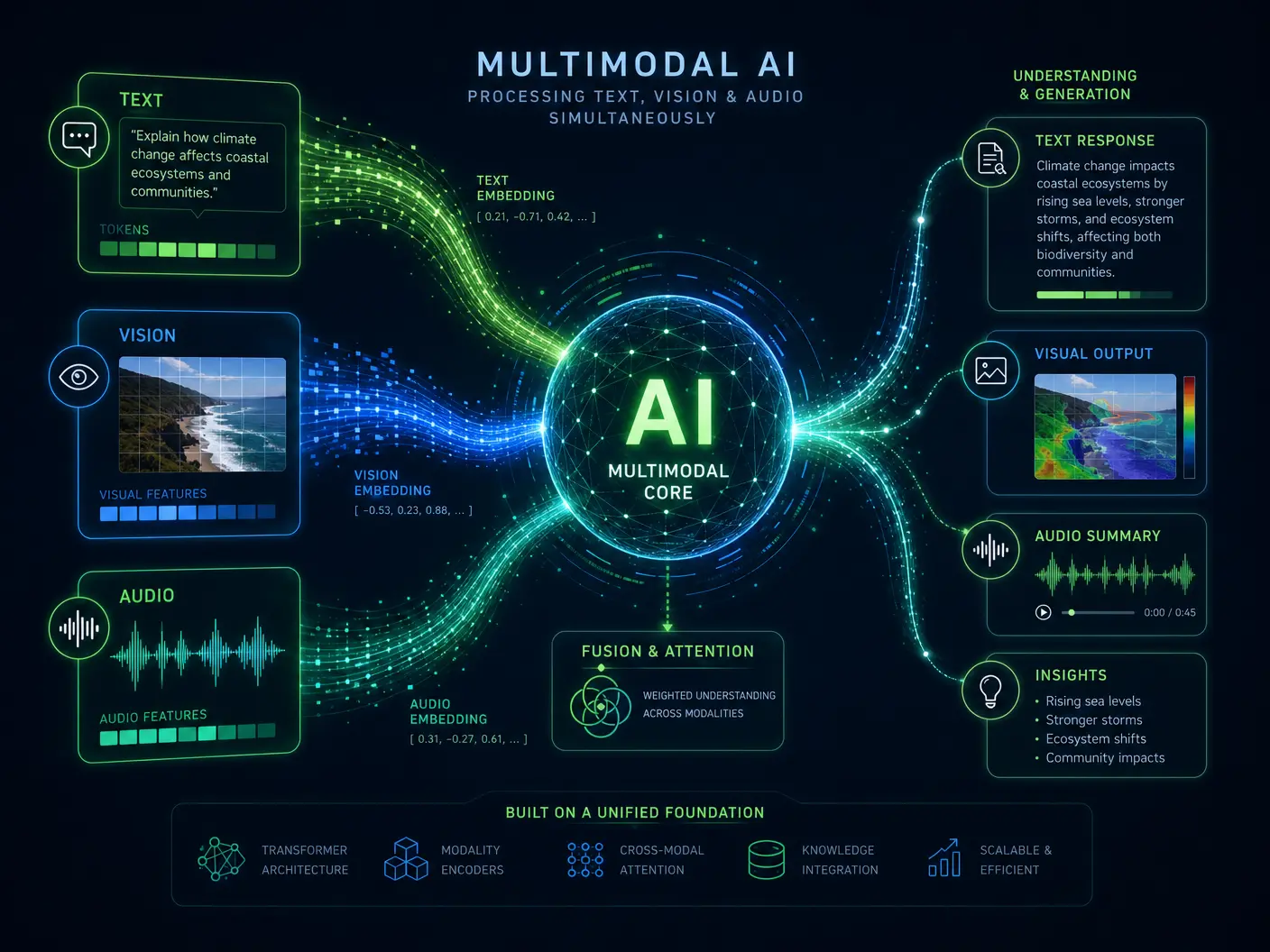
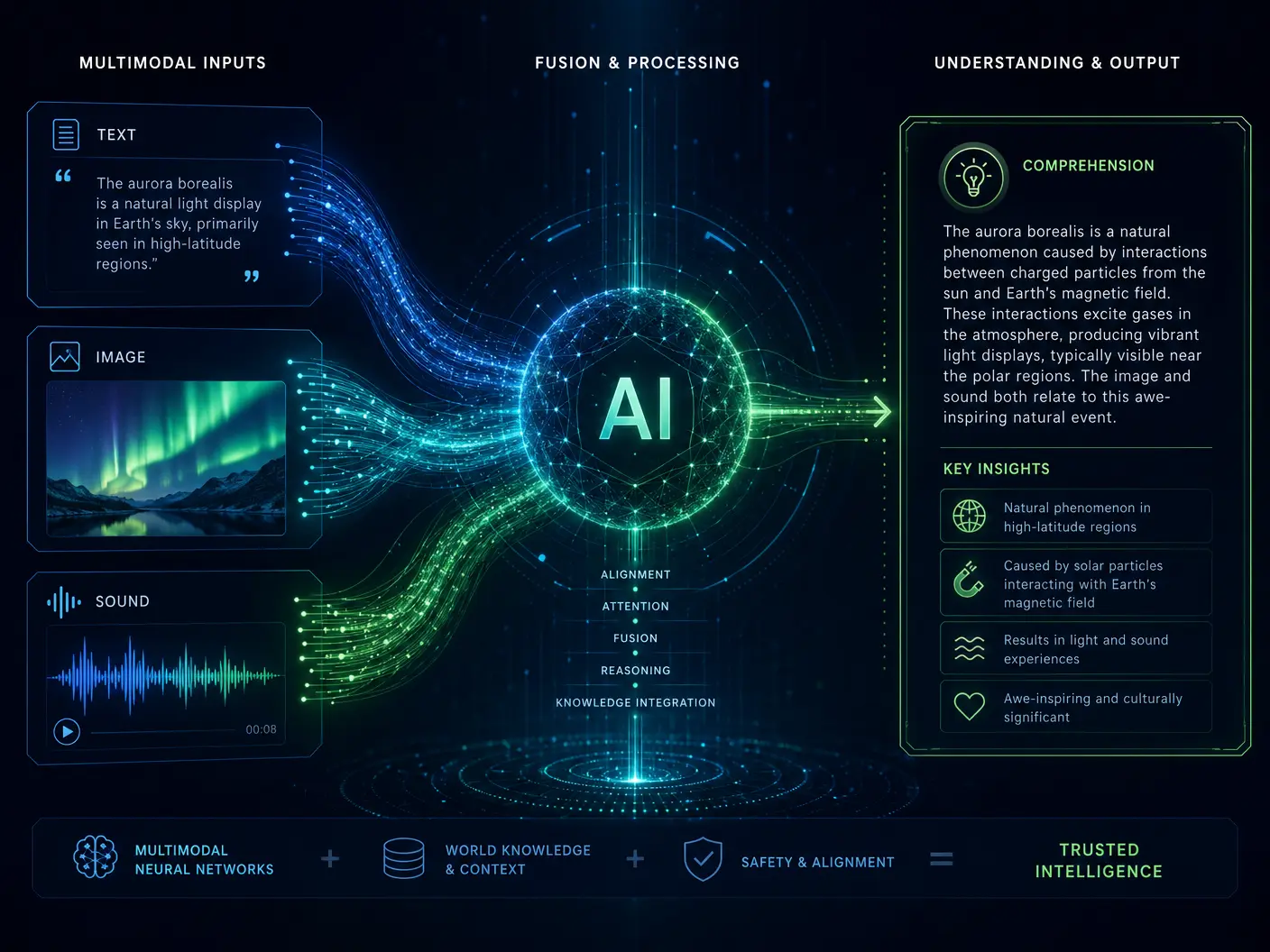
The human experience is inherently multimodal; we perceive and interact with our environment through a rich tapestry of sensory inputs. For AI to achieve a similar level of understanding and interaction, it must also be able to process and synthesize information from these diverse sources simultaneously. Multimodal models are designed to do just that, breaking down the silos between different data types and enabling AI to perceive context and meaning in a far more comprehensive way.
Beyond Single-Sense AI
For years, AI development progressed along specialized tracks. Natural Language Processing (NLP) models excelled at text, Computer Vision models at images, and Speech Recognition models at audio. While impressive in their respective domains, these systems often operated in isolation, lacking the ability to cross-reference information from different senses.
Multimodal models overcome this limitation by learning joint representations across different data types. This allows them to:
- Understand Context Richly: An image of a cat can be understood not just as a cat, but as a "fluffy cat playing with a red ball" when combined with textual descriptions.
- Generate Diverse Outputs: A single prompt can generate a coherent story, accompanying images, and even background music.
- Improve Robustness: Information from one modality can compensate for ambiguities or noise in another, leading to more reliable predictions.
- Enable Complex Interactions: AI can respond to spoken commands by performing physical actions, interpreting visual cues, and generating textual summaries.
This convergence is particularly evident in the rise of Vision-Language-Action (VLA) models, which are powering advancements in areas like humanoid robotics and complex agentic systems [1].
The Power of Integrated Intelligence
The impact of multimodal models is far-reaching, transforming how AI can assist and collaborate with humans. These models are becoming a "true partner" by boosting teamwork, enhancing security, accelerating research momentum, and improving infrastructure efficiency across various sectors [2].
Consider the implications for fields like healthcare, education, or creative industries. A multimodal AI could analyze a patient's medical images, read their electronic health records, listen to their symptoms, and even observe their physical demeanor to provide a more accurate diagnosis or treatment plan. In education, it could understand a student's written essay, interpret their diagrams, and listen to their verbal explanations to offer personalized feedback.
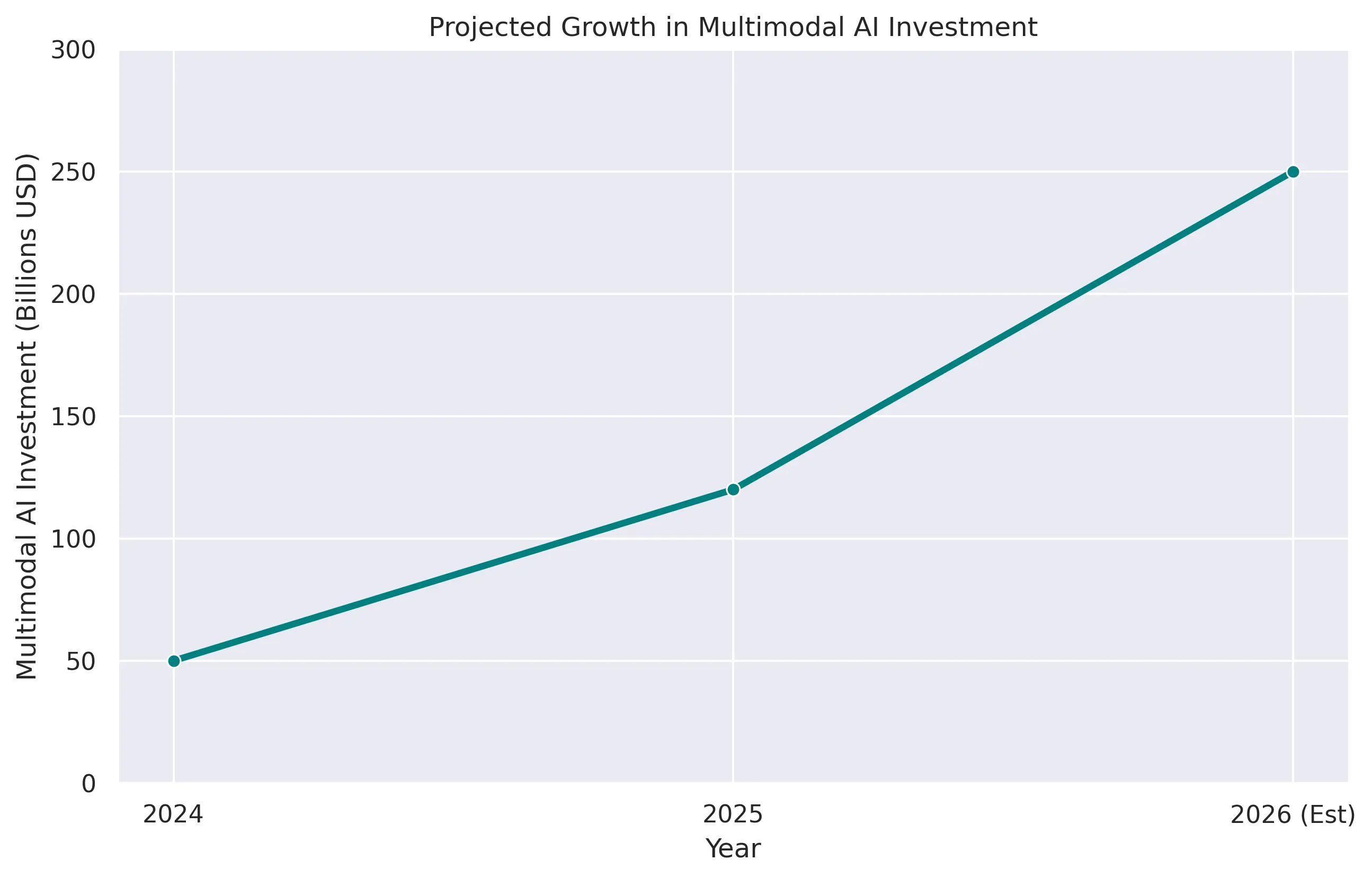
The development of these models is also driving significant economic activity. While specific figures for multimodal models are still emerging, the overall private AI investment reached $285.9 billion in the U.S. in 2025, indicating a robust ecosystem for advanced AI research and development [3]. GPT-5.4, a prominent example of an advanced generative AI, has already hit significant economic valuation milestones, showcasing the commercial viability and demand for highly capable, integrated AI systems.
Challenges and Future Directions
Despite their immense potential, multimodal models present unique challenges. Training these models requires vast and diverse datasets that are carefully curated and aligned across modalities. The computational resources needed for training and inference are also substantial, pushing the boundaries of current hardware capabilities.
Furthermore, ensuring consistency, coherence, and ethical behavior across different modalities is a complex task. Preventing biases present in one data type from propagating to others, and ensuring that generated content is safe and appropriate, are ongoing areas of research.
Future directions for multimodal AI include:
- Enhanced Cross-Modal Reasoning: Developing models that can perform more sophisticated reasoning tasks by integrating information from multiple senses.
- Personalized Multimodal Experiences: Creating AI systems that can adapt their multimodal interactions to individual user preferences and contexts.
- Real-time Multimodal Interaction: Reducing latency to enable seamless, instantaneous communication and collaboration between humans and multimodal AI.
- Embodied Multimodal AI: Integrating multimodal perception and action capabilities into physical robots for more natural and effective interaction with the physical world.
Conclusion
Multimodal Model Mastery is not just a trend; it is the future of Artificial Intelligence. By enabling AI to perceive, understand, and interact with the world through a rich combination of senses, we are unlocking unprecedented levels of intelligence and capability. In April 2026, these integrated AI systems are poised to become indispensable partners in every domain, transforming how we work, learn, and create. The journey towards truly holistic AI is well underway, promising a future where technology understands us, and our world, in profound new ways.
References
[1] Vishal Mysore. "The Biggest AI Trends and Tools Emerging in April 2026." Medium, April 2026.
[2] Microsoft News. "What's next in AI: 7 trends to watch in 2026." December 2025.
[3] Stanford HAI. "The 2026 AI Index Report." 2026.
[4] National University. "131 AI Statistics and Trends for 2026." March 2025.