Inference Memory Mastery
In the relentless pursuit of more powerful and capable Artificial Intelligence, a silent battle is being waged behind the scenes: the fight against memory bottlenecks during inference. As we delve into April 2026, the industry has recognized that simply building larger, more intelligent models is no longer enough. The true frontier of innovation lies in optimizing how these models operate in real-world scenarios, particularly concerning their memory footprint. This focus on "Inference Memory Mastery" is revolutionizing the deployment of large language models (LLMs) and other complex AI systems.
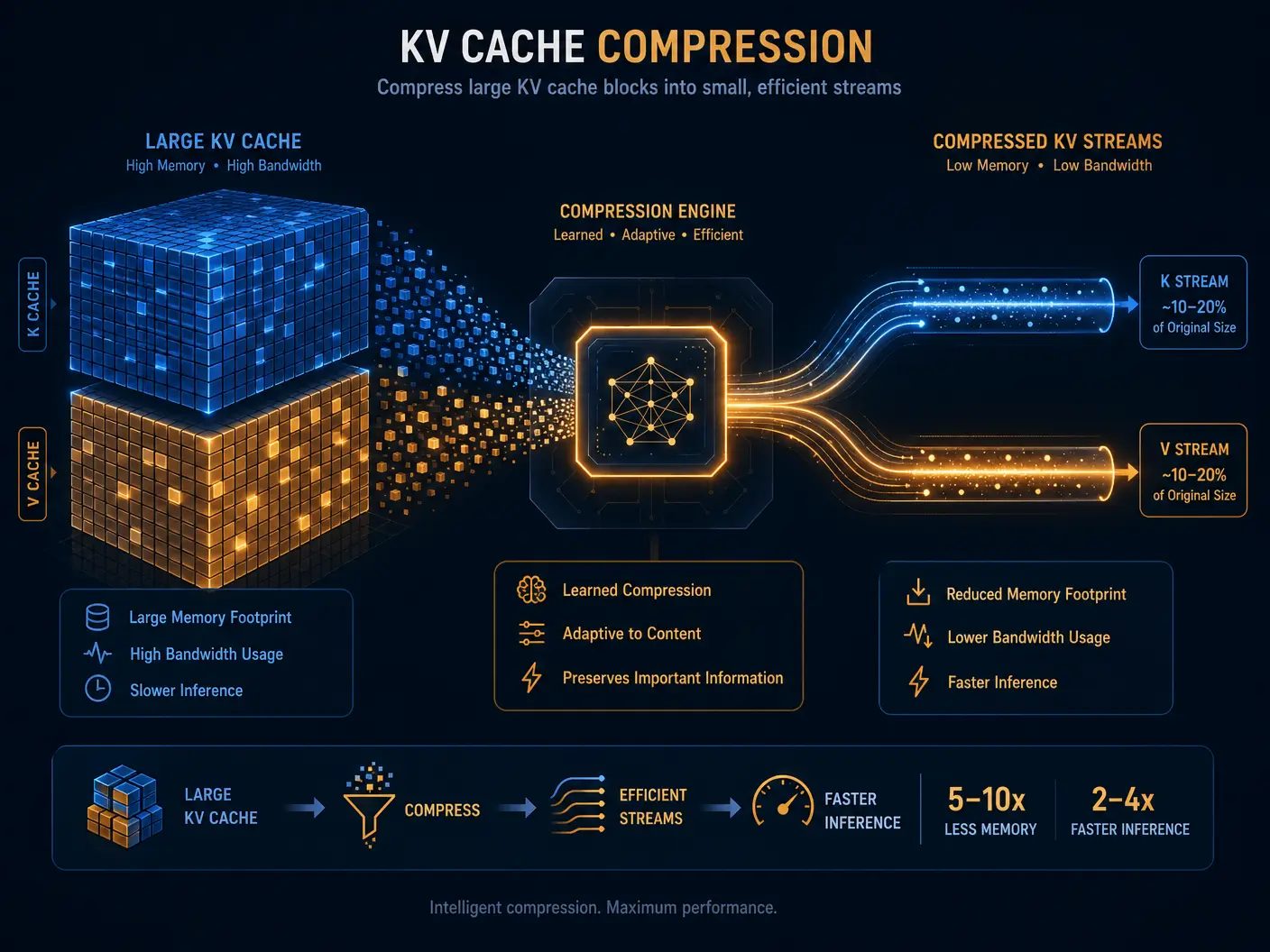
The challenge is clear: as context windows for LLMs expand to accommodate longer conversations and more intricate tasks, the memory required to maintain these contexts—specifically the Key-Value (KV) cache—skyrockets. This not only drives up operational costs but also limits the practical deployment of advanced AI on diverse hardware. The solution? Ingenious compression techniques that allow models to maintain vast amounts of context without overwhelming system resources.
The KV Cache Conundrum
Every time an LLM processes a sequence of tokens, it generates and stores keys and values for each token in its attention mechanism. This collection, known as the KV cache, is crucial for efficient generation, preventing the model from recomputing past tokens. However, the size of this cache grows linearly with the length of the input sequence, quickly becoming a significant memory hog.
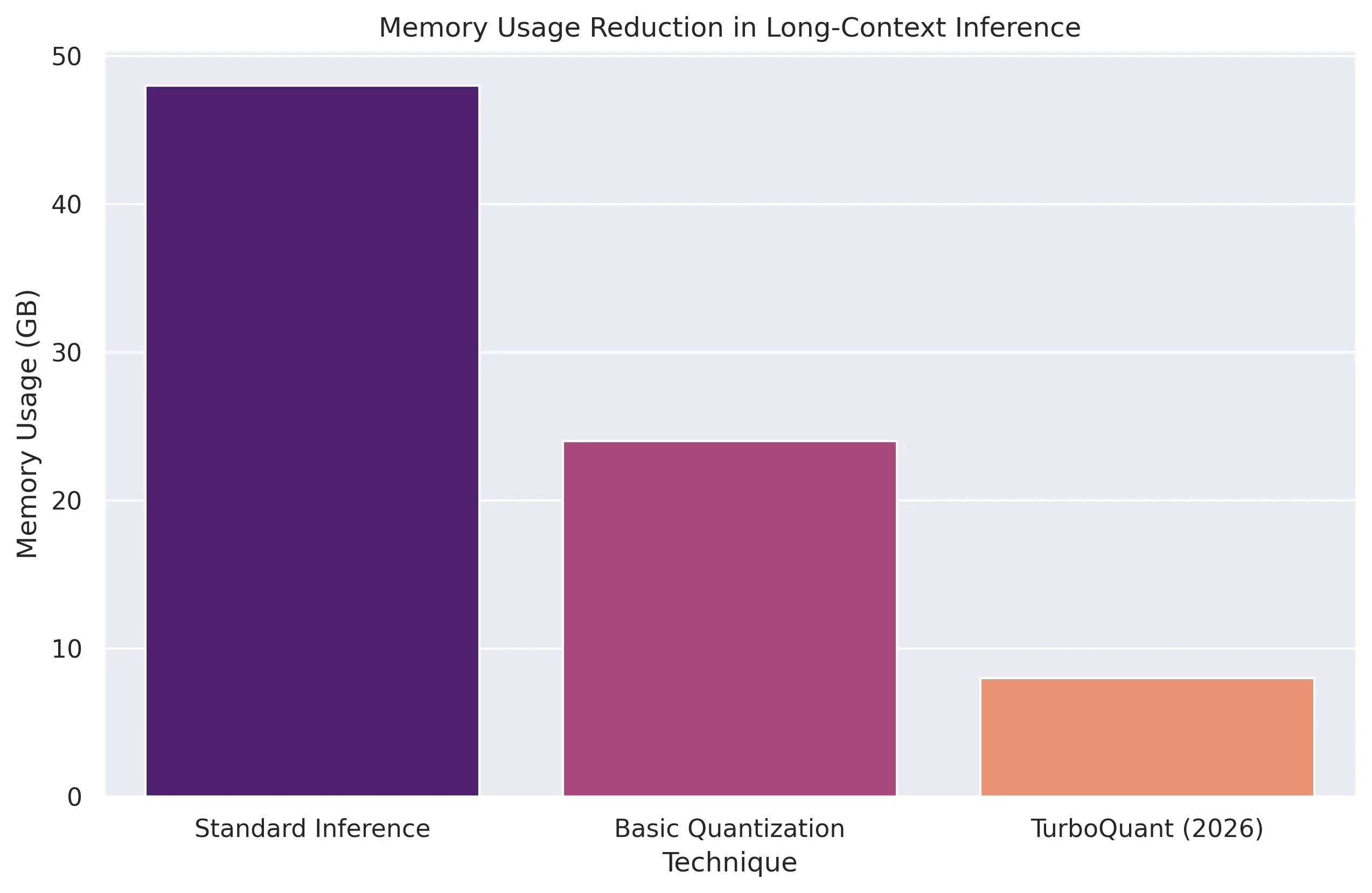
For models with context windows stretching into hundreds of thousands or even millions of tokens, the KV cache can consume gigabytes of GPU memory. This memory pressure translates directly into higher inference costs, limits batch sizes, and restricts the deployment of cutting-edge LLMs to only the most powerful and expensive hardware. The industry is no longer just asking, "How smart is the model?" but rather, "How efficiently can the model maintain context over long sessions?" [1].
TurboQuant: A Game Changer in Compression
One of the most significant breakthroughs in this area is TurboQuant, a research initiative from Google Research announced in March 2026. Unlike general-purpose model compression methods that focus on reducing the overall model size, TurboQuant specifically targets KV cache compression during inference. Its goal is to optimize the working memory used when LLMs process long contexts, without sacrificing performance.
Reports suggest that TurboQuant can achieve approximately 6x reductions in working memory requirements during inference [1]. This dramatic improvement has several profound implications:
- Improved Long-Context Efficiency: Models can handle much longer input sequences without performance degradation.
- Reduced GPU Memory Pressure: Frees up valuable GPU resources, allowing for larger batch sizes or the use of less expensive hardware.
- Lower Inference Costs: Directly translates to significant cost savings for organizations deploying LLMs at scale.
- Wider Accessibility: Enables the deployment of advanced LLMs on a broader range of devices and infrastructure.
This innovation is a testament to the industry's commitment to making powerful AI more practical and accessible. It underscores a shift in focus towards operational efficiency as a key differentiator in the AI landscape.
The Economic Impact of Efficiency
The economic benefits of inference memory optimization are substantial. By reducing the memory footprint and associated computational demands, companies can significantly lower their operational expenditures for AI deployments. This directly contributes to the overall productivity gains seen across industries, where AI is expected to improve employee productivity by 40% and 60% of business owners believe it will increase their productivity [3].
As organizations continue to scale their AI initiatives, the ability to run more powerful models with less memory will be a critical competitive advantage. It allows for faster iteration, more complex applications, and ultimately, a greater return on AI investments.
Beyond TurboQuant: The Future of Efficiency
While TurboQuant represents a major leap forward, the field of inference memory optimization is continuously evolving. Researchers are exploring other techniques such as sparse attention mechanisms, dynamic KV cache management, and novel quantization methods tailored for inference. The goal is to create a future where AI models can process virtually unlimited contexts with minimal memory overhead.
This ongoing innovation is crucial for the development of truly autonomous AI systems and the broader adoption of AI across all sectors. The focus on efficiency ensures that the incredible capabilities of modern AI are not limited by hardware constraints or prohibitive costs.
Conclusion
Inference Memory Mastery, exemplified by breakthroughs like TurboQuant, is a pivotal trend in the AI landscape of April 2026. By addressing the critical challenge of KV cache memory, these innovations are making advanced large language models more efficient, cost-effective, and widely deployable. This focus on operational excellence is not just about technical prowess; it's about unlocking the full economic and transformative potential of AI, ensuring that intelligence is not just powerful, but also practical and pervasive.
References
[1] Vishal Mysore. "The Biggest AI Trends and Tools Emerging in April 2026." Medium, April 2026.
[2] NVIDIA Blog. "How AI Is Driving Revenue, Cutting Costs and Boosting Productivity." March 2026.
[3] National University. "131 AI Statistics and Trends for 2026." March 2025.
[4] Deloitte US. "The State of AI in the Enterprise - 2026 AI report." 2026.