Groq: Pioneering Ultra-High-Speed AI Hardware for Next-Gen Machine Learning Workloads
Learn about the strategic decisions, technical challenges, and market dynamics that shaped this AI startup's journey.
Groq: Pioneering Ultra-High-Speed AI Hardware for Next-Gen Machine Learning Workloads
Groq: Pioneering Ultra-High-Speed AI Hardware for Next-Gen Machine Learning Workloads
Status
Success
Problem Solved
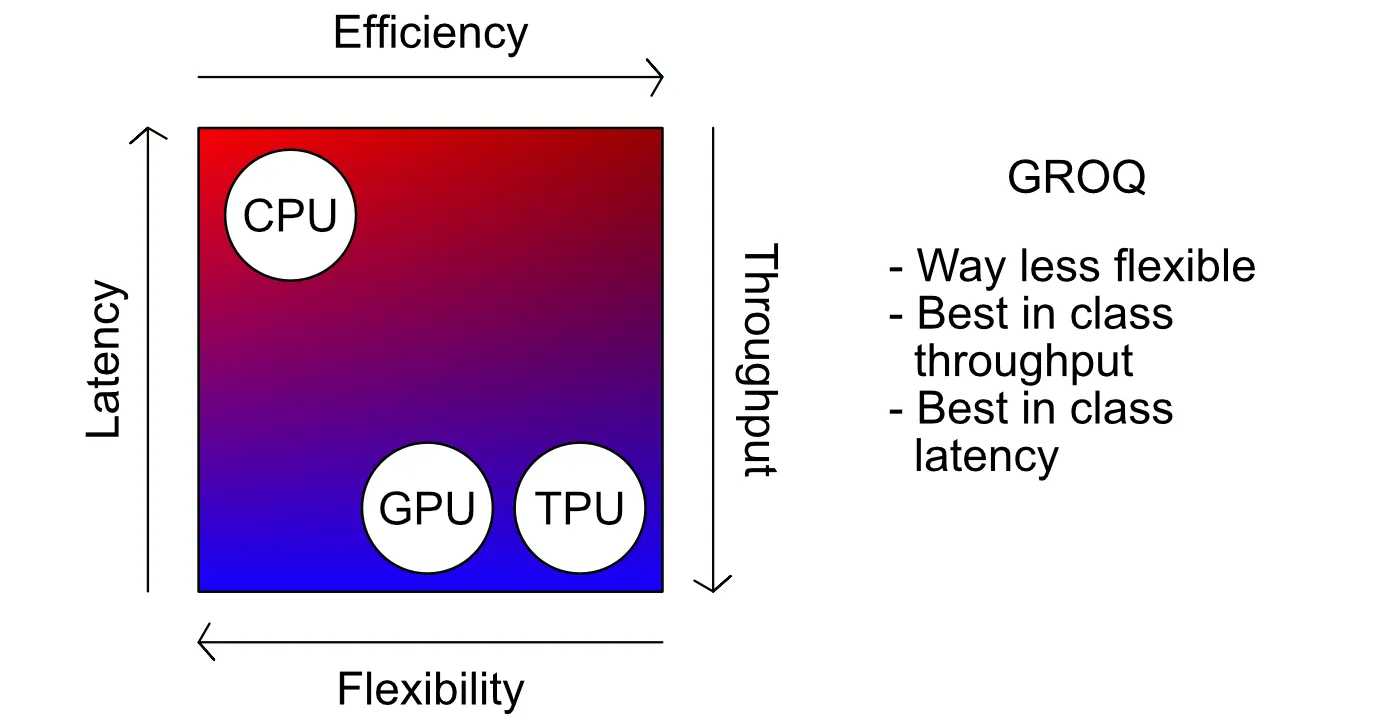
The exponential growth of AI models and their computational demand outpaced the capabilities of traditional hardware accelerators like GPUs and TPUs. Groq addresses the problem of high-latency and limited throughput in AI inference and training workloads by developing a novel chip architecture designed explicitly for deterministic, ultra-low-latency, high-throughput machine learning tasks.
Why it Succeeded
Groq succeeded because of its unique approach to AI hardware design, focusing on deterministic single-instruction, multiple-thread (SIMT) execution that simplifies programming while maximizing throughput. Their hardware architecture avoids bottlenecks common in GPU designs by implementing a rethought compute fabric optimized for inference and training at scale. Strategic leadership, strong IP, and early partnerships in the AI ecosystem bolstered Groq's market credibility.
Funding and Evaluation
Total Funding: Approximately $375 million across multiple funding rounds.
Peak Valuation: Estimated valuation over $1 billion, reaching unicorn status.
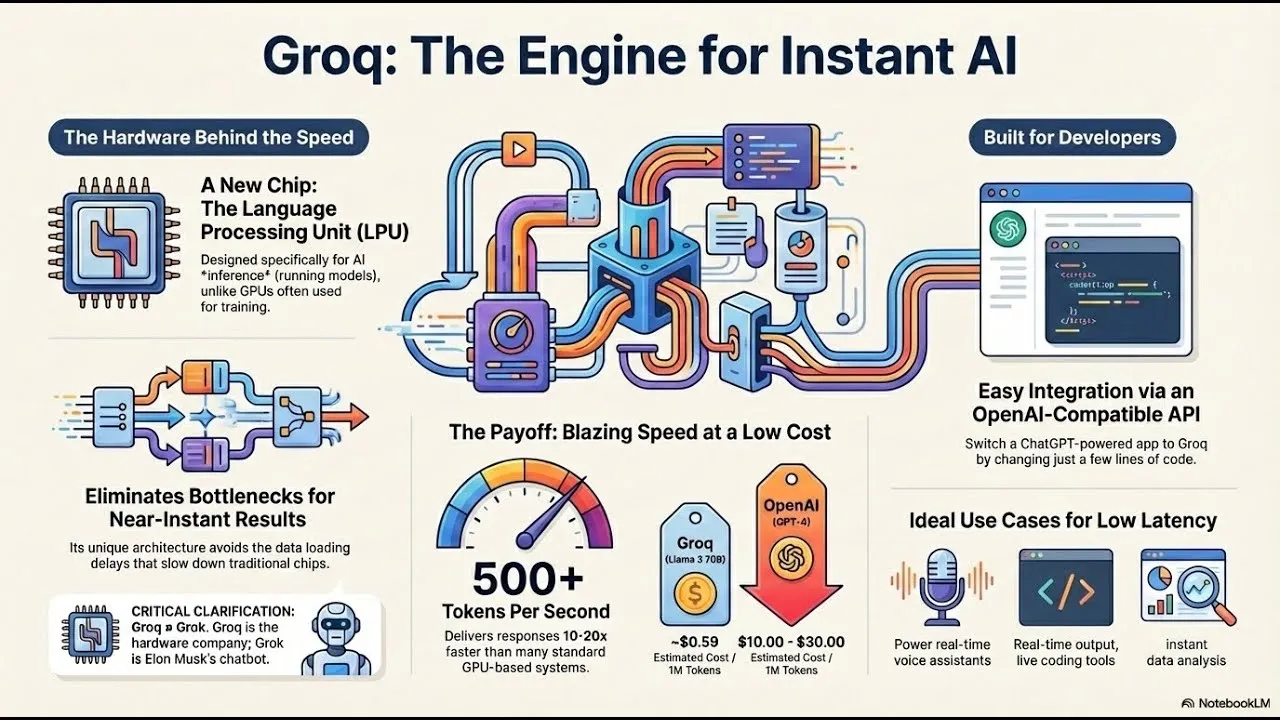
How it Works (Technical Overview)
Groq’s chip architecture reimagines AI processing using a simplified, deterministic compute engine. Key technical points include:
Perspective
Groq represents a distinct and promising evolution in AI hardware. Their dedication to solving latency and throughput challenges through architectural innovation offers compelling advantages over incumbent GPU-centric solutions. By targeting both edge and data center use cases, they address a broad market spectrum. While competition is fierce, Groq’s focus on software simplicity and deterministic performance helps carve out a niche for applications requiring both speed and reliability. Continued execution and ecosystem development will be critical, but their success underscores the demand for specialized AI acceleration beyond general-purpose GPUs.
Key Investors: Andreessen Horowitz, Google Ventures, Tiger Global, DCVC (Data Collective), and Redline Capital among others.
Tensor Streaming Processor (TSP): A single-threaded processor executing massive numbers of operations in a deterministic manner, eliminating the need for complex control logic.
SIMT Execution Model: Unlike warp-based GPU threading, Groq uses single instruction multiple thread execution where all threads perform the same instruction in lockstep, reducing overhead.
Massive Parallelism: The chip contains thousands of cores optimized for matrix math operations fundamental to AI workloads.
Minimal Software Complexity: By reducing microarchitectural variance and nondeterminism, Groq enables easier software development and debugging.
High Memory Bandwidth: Customized memory hierarchies and direct data flow minimize latency.
Focus on Latency and Throughput: Designed not just for raw FLOPs but consistent, predictable high-throughput inference and training.